
Web crawler
Import content items from crawling web pages
This data source allows you to provide a number of URLs to web pages that the Meya web crawler will crawl and import. The Meya web crawler will follow and crawl all web links found on each downloaded web page until it has reached a specified page limit.
In addition to following links, the Meya web crawler will also try download the robots.txt file for each unique domain it encounters to ensure it adheres to the crawling rules defined by the web administrators of each domain.
This data source also provides a number of parameters that can be used to control the Meya web crawler, the following sections will describe each field and how to use it in more detail.
Start URLs
This field contains a list of URLs to web pages that the Meya web crawler will start its crawl at. Each web page will be downloaded and parsed.
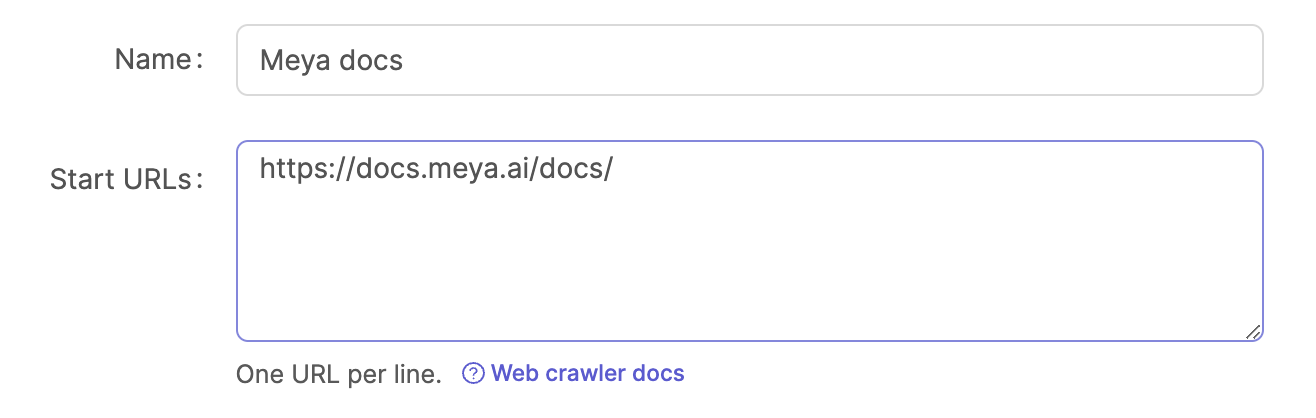
For each start URL and each web link URL extracted from each web page, the following rules are applied:
- The URL is ignored if it's been crawled already i.e. it's deduped.
- The URL is ignored if it's not in the Allowed domains(s) list.
- The URL is only imported if it matches one of the patterns in the URL pattern(s) list.
- The URL is ignored if it matches a rule defined in the domain's
robots.txtfile:- Each unique domain's
robots.txtfile is always evaluated. - If you wish the Meya web crawler to ignore the
robots.txtrules for a URL, then you can add a URL pattern in the Ignore robots.txt patten(s) field.
- Each unique domain's
- The URL is ignored if it matches a pattern defined in the Exclusion pattern(s) list.
Max pages
This is the maximum pages that the Meya web crawler will import. Meya imposes a maximum page limit per crawler for your account, but you can set this to a lower amount if you want to hard limit the Meya web crawler.
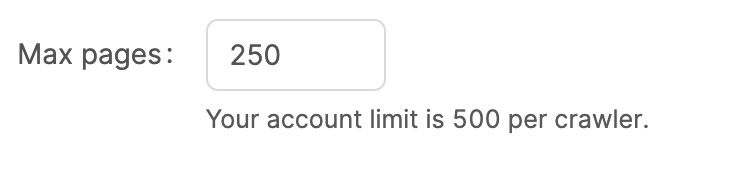
Setting the max pages limit to a low limit e.g. 10 is useful if you want to test your configuration and see if the correct pages are imported before doing a full crawl and index.
Depth limit
The Meya web crawler will follow each web link found a web page it successfully downloads and parses, this field controls how many pages deep the web crawler may go. You can use the limit and the Max pages limit to finely control how "far" or "broad" the web crawler can crawl.

Allowed domains
This allows you to restrict the Meya web crawler to only crawl URLs that match certain domains. This is very useful to make sure the web crawler stays on certain sites and don't crawl other web sites such as social media sites, news sites etc.
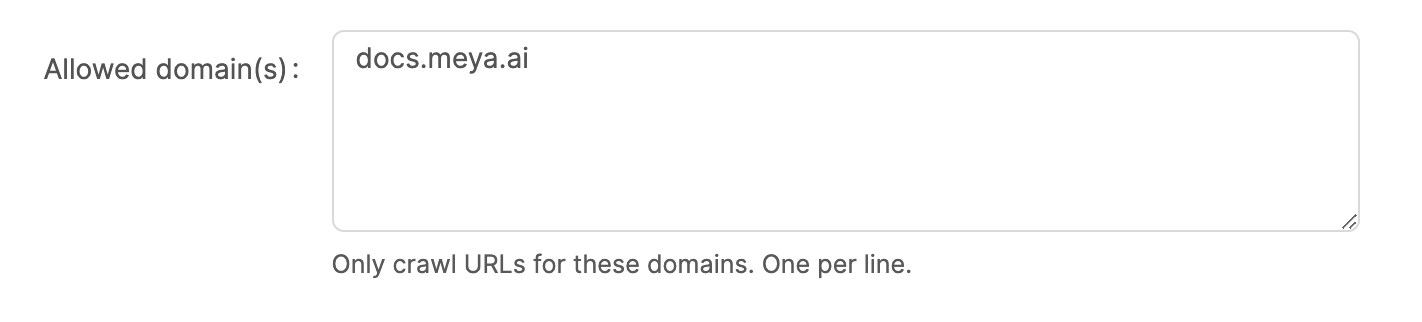
Note that these are the domain names only and not fully qualified URLs.
URL patterns
This allows you to define regex patterns to match specific URLs that you would like to be crawled and indexed.

Note that these regex patterns must be valid Python regex patterns. We recommend using the Pythex regex tool to help you write and test URL regex patterns.
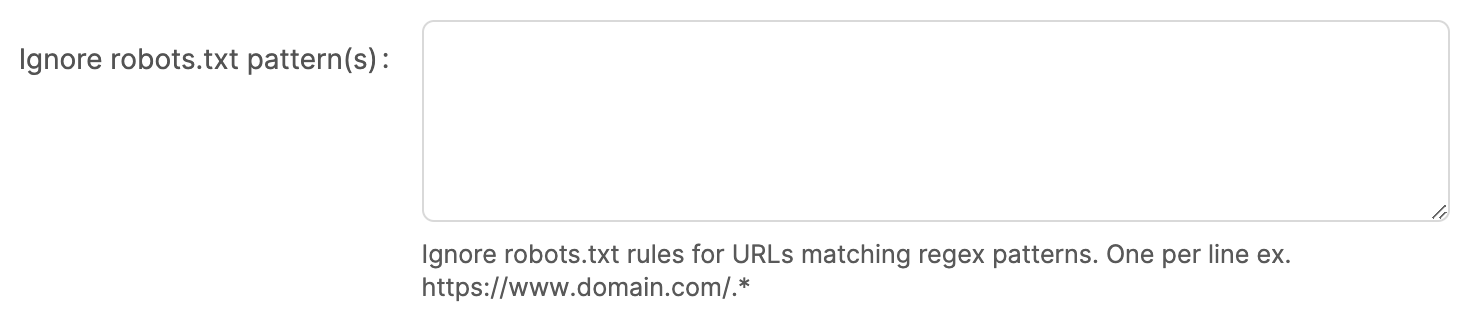
Ignore robots.txt patterns
By default, the Meya web crawler will download and evaluate the robots.txt file for each unique domain found in all the URLs in the start URLs as well as each web link URL parsed. Before each URL is crawled its first evaluated against the rules defined in the domain's robots.txt file. It is best practice for a web crawler to always adhere to the robots.txt rules (in some cases the website might block the crawler if it ignores the robots.txt file), however, in some situations you might want to explicitly ignore the robots.txt rules for particular URLs.
This field allows you to provide a list of URL patterns that should ignore the robots.txt rules.
Import
Once you've configured your data source you can click on the Crawl & import button to start the Meya web crawler. A couple of things happen when you start the import process:
- The fields are validated and saved. The web crawler will not start if there are any validation errors.
- The Meya web crawler will start crawling your start URLs - this can take a couple of minutes depending on the page limit and depth limit.
- Once the Meya web crawler is done, it will automatically start the indexer to chunk and index all the newly imported content items.
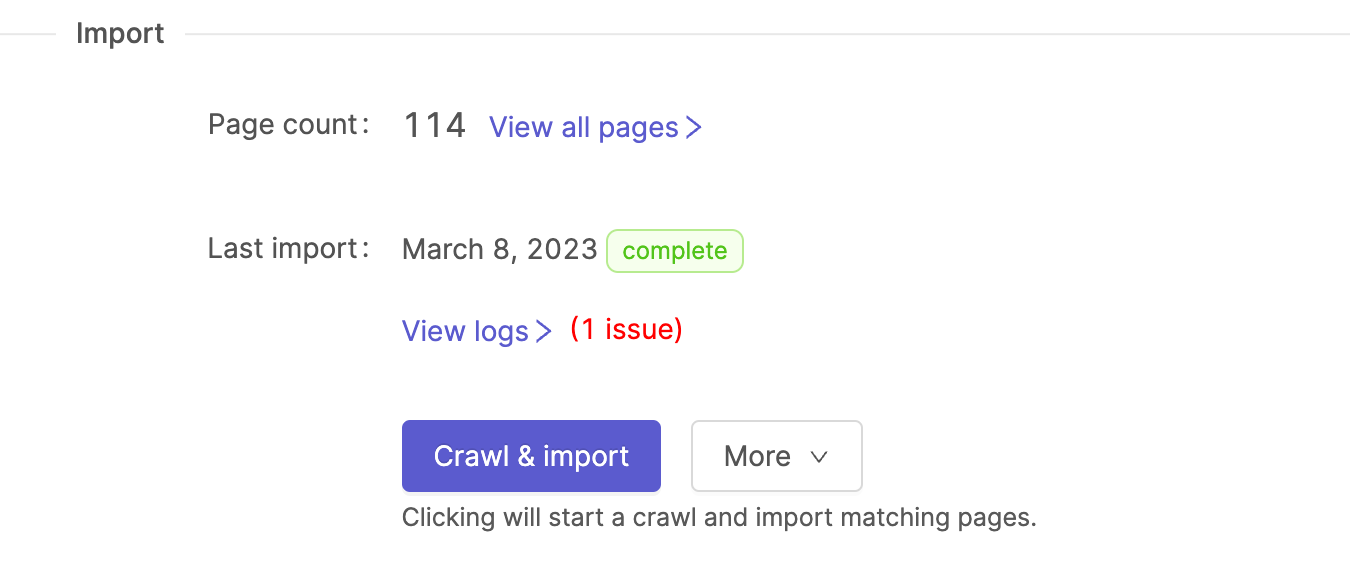
Once the import job is complete, you can view all the imported content items by clicking on the View all pages link.
Updated about 2 months ago