
Prompt template
Customize your question prompt
When you use the OpenAI question component in BFML, the component will use a default prompt template to generate a LLM prompt that contains the user's questions, any related content chunks from your content repository, and part of the user's transcript (this is only applicable with for ChatML based models such as gpt-3.5 and gpt-4).
In the OpenAI integration page you are able to create your own LLM prompt template that overrides the system default. In this prompt template you can use Meya's Jinja2 template syntax to customize the template.

Name
This is just a descriptive field that you can use for you reference. This is useful to keep track of different templates if you're experimenting with different templates, models or hyperparameters.
Version
This is a meta field that allows you to keep track of template versions in the logs if your experimenting with multiple templates.
Active
This checkbox specifies whether the template is active or not. There are a couple conditions to bear in mind:
- No active templates: the system default template will be used.
- One active template: that template will be used for all
questioncomponent queries. - Multiple active templates: the
questioncomponent will randomly select between all the active templates. This is useful if you would like to A/B test between different prompt templates.
Template
This will allow you to customize the template used to generate the prompt and allows you to use Meya's Jinja2 template syntax that you use in BFML.
ChatML template
For newer models such as gpt-3.5 and gpt-4 OpenAI implements a ChatML structure to generate text completions. For these prompts the template must be valid YAML code with the correct field annotations such as role and content.

Current limitations
The template allows you to control the content chunks as well as the specific prompt instructions, however, the template does not allow you to control the included chat transcript. The chat transcript is always pre-pended to list of messages in the template.
questioncomponent settings
You can control the amount of transcript messages and chunks to include in the prompt template by setting the following fields in the question component:
max_content_chunks: this will determine how many related content chunks are added that the LLM will use to generate an answer from.min_event_history: the minimum number of transcript events to include in the prompt.max_event_history: the maximum number of transcript events to include in the prompt.
Text template
For older OpenAI text completion models such as text-davinci-003 the prompt template does not support the ChatML format and is simply a block of text.
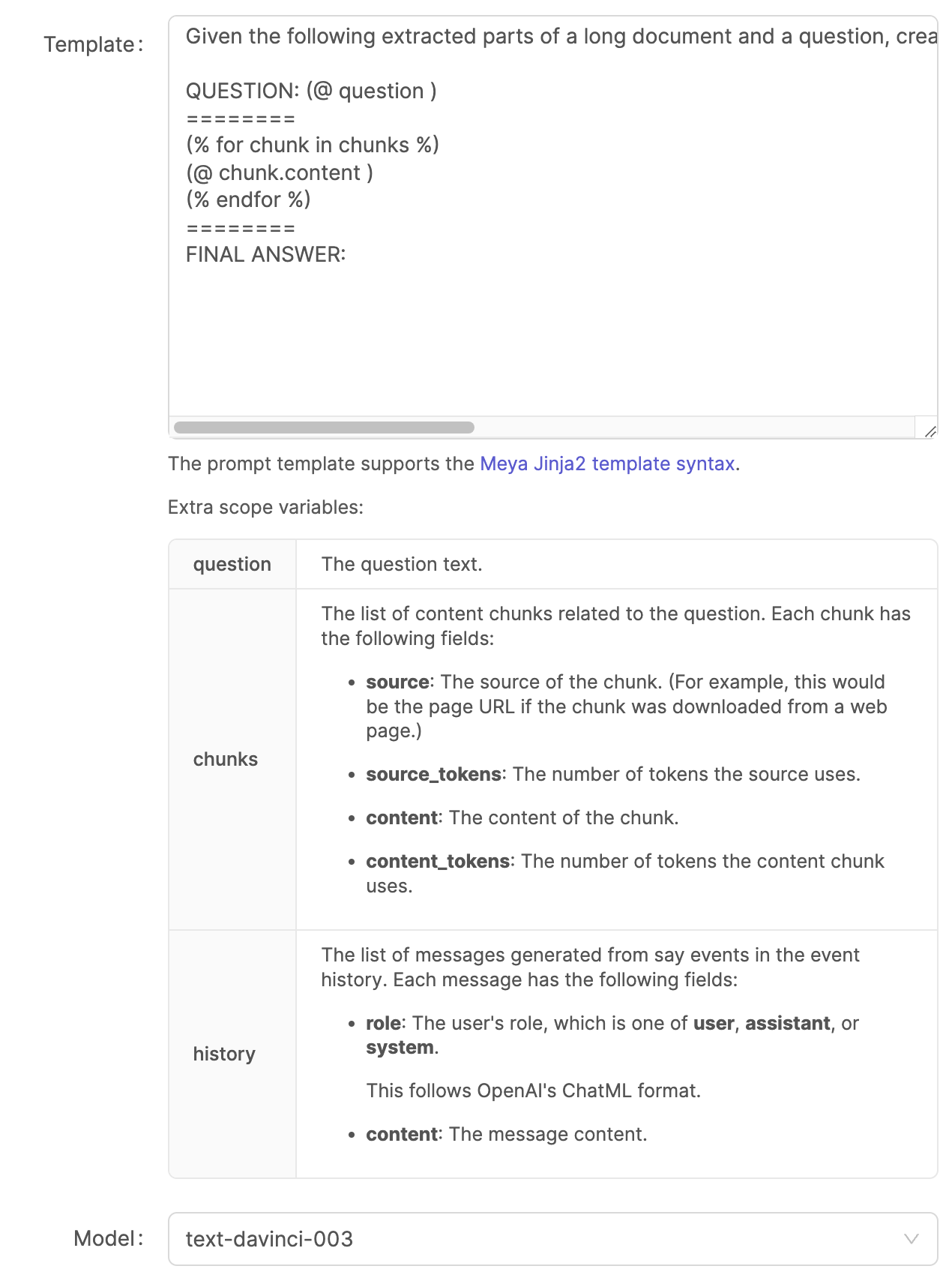
Current limitations
Currently it is not possible to add transcript history to this template.
Model
The specific OpenAI model to use for the prompt template. Note, the template will automatically change based on whether the model supports ChatML or not.
GPT-4Currently GPT-4 access is to subject to early access. Meya does have access to GPT-4 if you use Meya's OpenAI API key, however, this is only available for
devapps.If you would like to launch your app to production with a
productionapp, then you will need your own OpenAI API key that has access to GPT-4.
Hyperparameters
This is a simple JSON object that allows you to set the model's specific hyperparameters. Please check OpenAI's model documentation to see what each parameter does.
Check question component answers
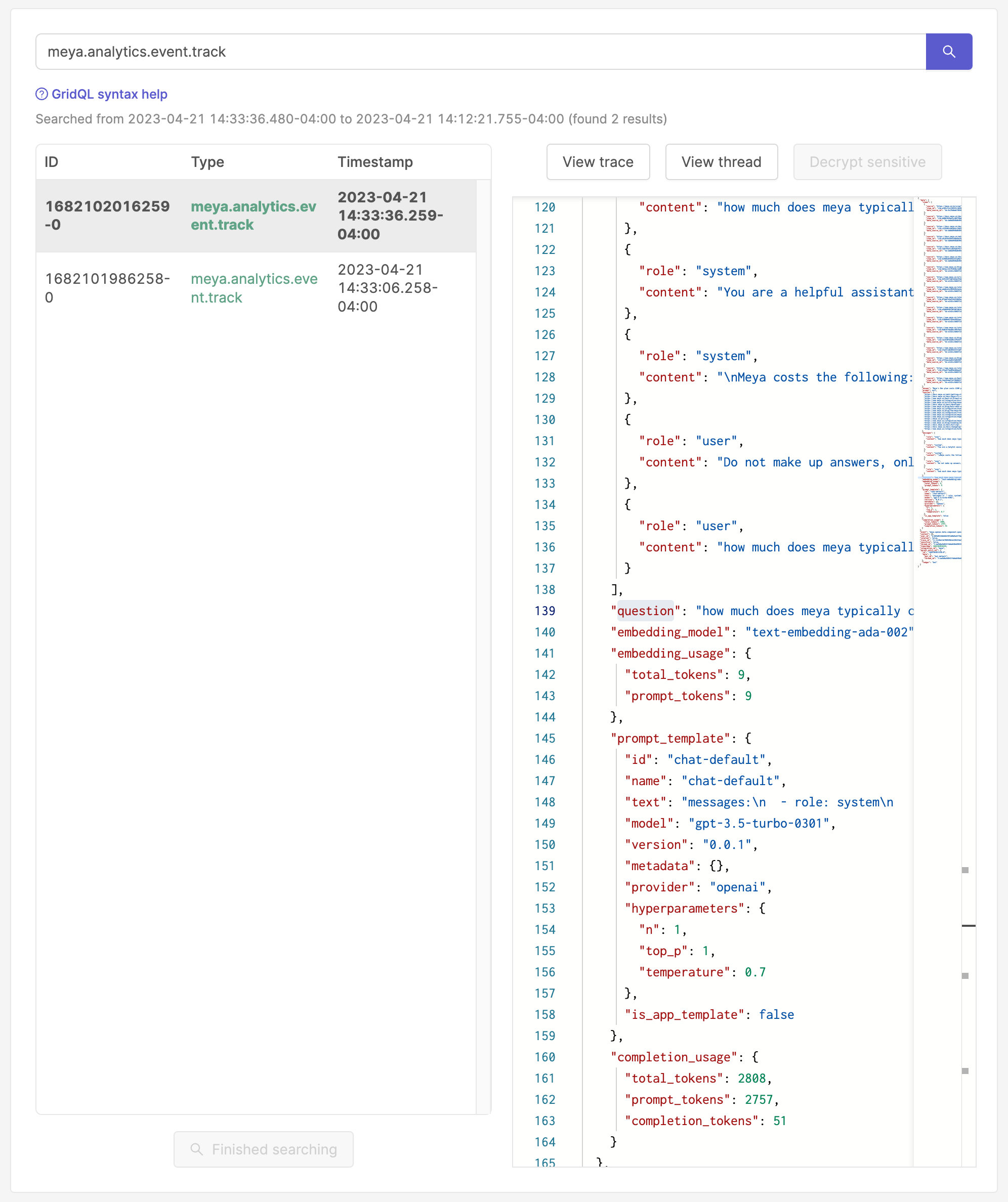
question component answersThe question component always logs a detailed meya.analytics.event.track event for each question/answer response. This is very useful to analyze the quality of the answers that are generated for the different prompt templates.
You can filter for events using the following GridQL: meya.analytics.event.track
This will show detailed information about the prompt template used, the embedding model used and the chunks used as context.
Why use ameya.analytics.event.trackevent?
The question component uses an standard analytics event because this allows you to configure an analytics integration such as Segment to stream these events into your own data pipeline for further analysis.
Updated 2 months ago