
URL list
Import content items from a list of URLs
This data source allows you to provide a number of explicit URLs that the Meya web crawler will crawl and import. Unlike the Web Crawler data source, the Meya web crawler will not follow any links found on the crawled web pages.
The sections below will describe each field and how to use it in more detail.
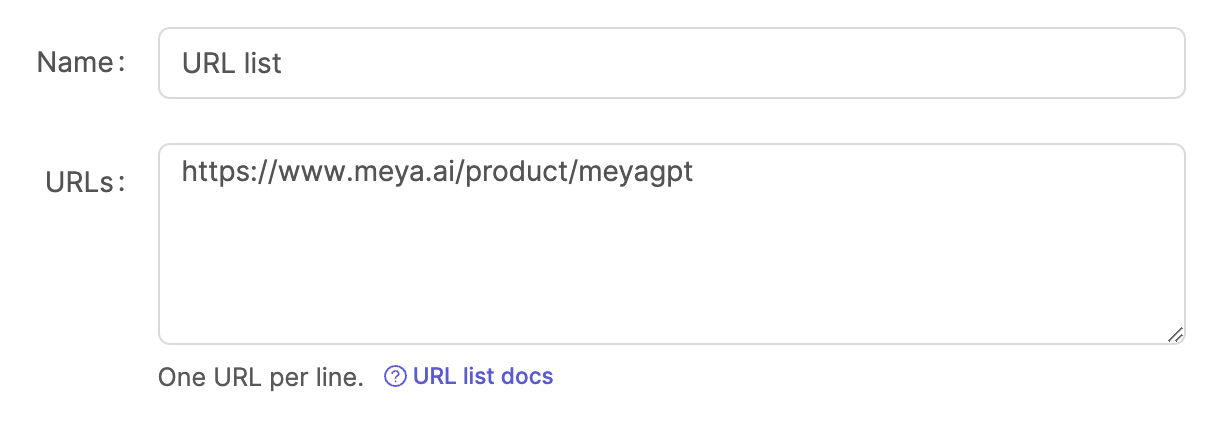
URLs
This field contains a list of URLs that the Meya web crawler will download and parse.
Import
Once you've configured your list of URLs you click on the Import URL list button to start the Meya web crawler. The following will happen:
- The fields are validated and saved. The web crawler will not start if there are any validation errors.
- The Meya web crawler will start downloading each web page, parse the web page and convert it into a content item in Markdown format.
- Note, that files such as PDFs, Word Docs or Spread Sheets will not be parsed.
- Once the Meya web crawler is done, it will automatically start the indexer to chunk and index all the newly imported content items.
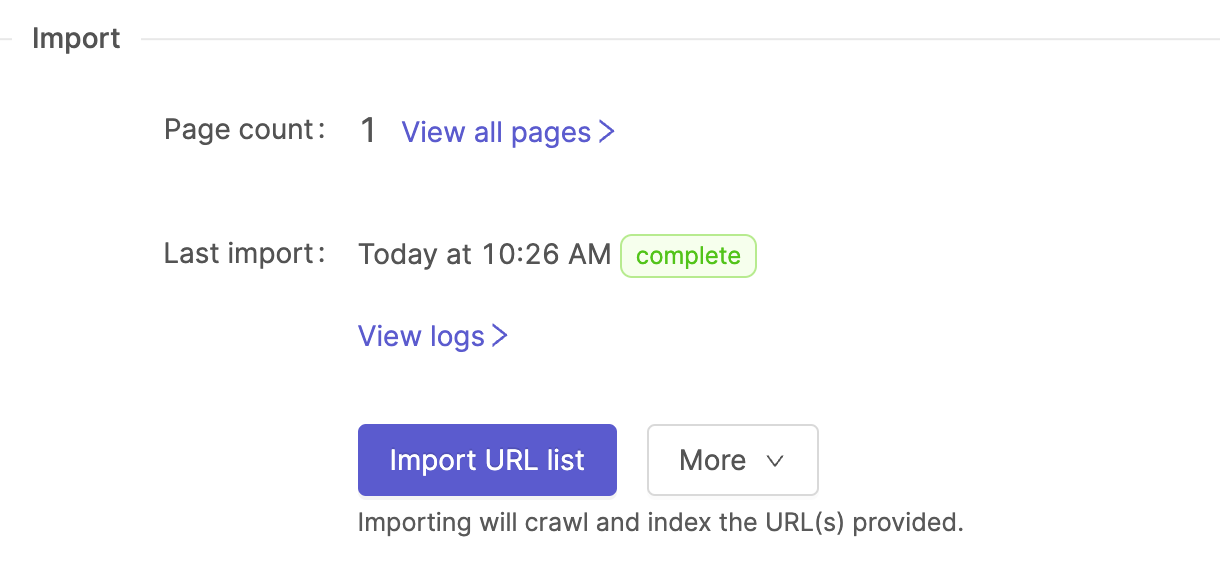
Once the import job is complete, you can view all the imported content items by clicking on the View all pages link.
Updated 2 months ago